



本文涉及的脚本源码也可以在git中获取:https://gitee.com/talonshaw/CodeLib_Python.git
背景
本文字库制作用于STM32驱动TFT显示,通常我们会将字库文件直接存储到外置falsh芯片,然后读取flash来显示文字。
由于ASCII字符要求在无外置flash时也要支持显示,并且ASCII字库较小,故这里将其制作为C语言数组,直接编译到单片机flash中。
本文对比介绍了两种字库制作软件。
方法1:使用TS4字模软件制作
优点:可用
缺点:收费
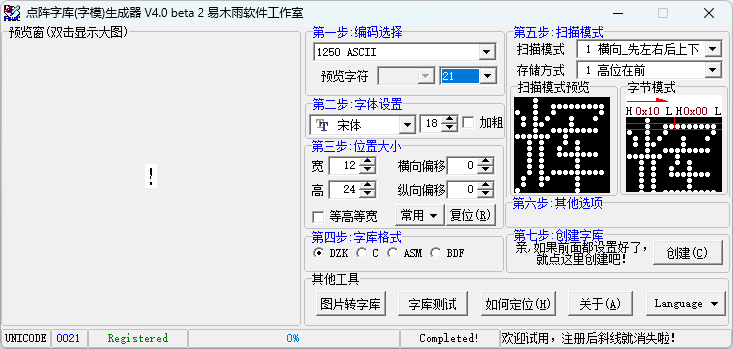
第一步:制作字库
编码:由于是英文字库,编码选择ASCII
字体设置:字体选择需要选等距的,测试比较合适的等距字体:
宋体
AgencyFB
Consolas
DejaVu_Sans_Mono
OCR_A
扫描模式:根据下位机驱动扫描模式选择
第二步:转换c数组
TS4本身支持输出C数组,但是格式与我的驱动不匹配,故这里自行转换实现。使用python转换:
CodeLib_Python\fontbin_to_c(ts4)\fontbin_to_c.py
import sys
import os
def bin_to_c_array(bin_file):
with open(bin_file, 'rb') as f:
data = f.read()
# ascii为0~127
height = int(len(data) / 128 / 2)
width = int(height / 2)
print("size: {}x{}".format(height, width))
# 跳过前32个非打印字符
start = 32 * height * 2
data = data[start:]
array_size = height * 2
c_file_name = os.path.splitext(bin_file)[0] + '.c'
array_name = os.path.splitext(bin_file)[0]
with open(c_file_name, 'w') as f:
f.write(f'#include <stdint.h>\n\n')
f.write(f'const uint16_t {array_name}[] = {{\n')
for i in range(0, 95): # 会输出" "到"~"共计95个字符
f.write(' ')
for j in range(height):
value = (data[array_size * i + j * 2] <<
8) | data[array_size * i + j * 2 + 1]
f.write(f'0x{value:04X}')
if j < height - 1:
f.write(', ')
f.write(f', /* {chr(i + 32)} */\n')
f.write('};\n')
if __name__ == '__main__':
if len(sys.argv) < 2:
print(f'Usage: python {sys.argv[0]} [bin_file]')
sys.exit(1)
bin_file = sys.argv[1]
bin_to_c_array(bin_file)
方法2:使用正点原子ATK_XFONT字模软件制作
优点:免费,界面现代;除了生成字库还可以用于制作字模;制作中文字库好用。
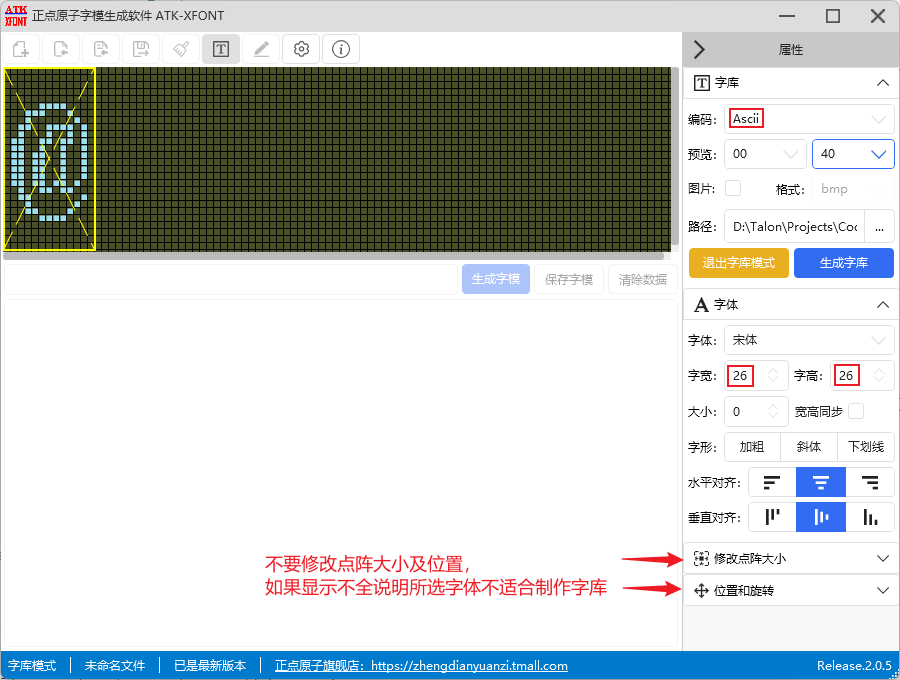
缺点:英文字库存在对齐问题。只能居中或上下对齐,如abp,无论居中还是上下对齐均是不对的,期待改进。如下图:
第一步:制作字库
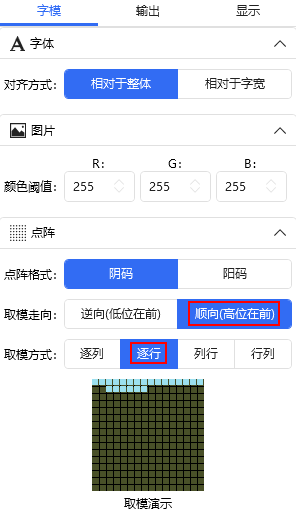
打开设置配置为顺向、逐行:
第二步:转换c数组
ATK_XFONT字库不支持直接输出C数组,使用python转换:
CodeLib_Python\fontbin_to_c(yuanzi)\fontbin_to_c.py
import sys
import os
def bin_to_c_array(bin_file):
with open(bin_file, 'rb') as f:
data = f.read()
# ascii为0~127,但实际原子输出的是1~126
height = int(len(data) / 126 / 2)
width = int(height / 2)
print("size: {}x{}".format(height, width))
# 跳过前31个非打印字符(由于实际输出1~126,所以是前31)
start = 31 * height * 2
data = data[start:]
array_size = height * 2
c_file_name = os.path.splitext(bin_file)[0] + '.c'
array_name = os.path.splitext(bin_file)[0]
with open(c_file_name, 'w') as f:
f.write(f'#include <stdint.h>\n\n')
f.write(f'const uint16_t {array_name}[] = {{\n')
for i in range(0, 95): # 会输出" "到"~"共计95个字符
f.write(' ')
for j in range(height):
value = (data[array_size * i + j * 2] <<
8) | data[array_size * i + j * 2 + 1]
f.write(f'0x{value:04X}')
if j < height - 1:
f.write(', ')
f.write(f', /* {chr(i + 32)} */\n')
f.write('};\n')
if __name__ == '__main__':
if len(sys.argv) < 2:
print(f'Usage: python {sys.argv[0]} [bin_file]')
sys.exit(1)
bin_file = sys.argv[1]
bin_to_c_array(bin_file)
评论区